さて、前回概要や成果物のイメージを説明してきました。
前回記事をご確認いただけていない方は、以下の記事をご確認ください。
全体像をざっくりと頭に入れていただいた上で、具体的に何をしていくかを今後説明していきます。
まず今回は環境や利用APIの設定などの手順の説明です。正直手順なのでググってもらえればわかる部分も多数含んでいますが、ご容赦ください。
手順概要
まずはざっくりと手順の概要を説明します。個別に追加説明が必要なものだけ後から追加説明を加えていきます。
1.localにpythonの開発環境を作る(venvでもvirtualenvでもなんでも) 2.GCPでプロジェクトを作成 3.プロジェクトでSpeech To text APIを有効にする 4.認証情報を作成する 5.作成されたcredentialを開発環境下におく 6.terminalでexport GOOGLE_APPLICATION_CREDENTIALS=“[PATH]“で環境変数にcredentials.jsonを入れておく 7.terminalで必要なlibraryをインポートする(pip or gitで引っ張ってきてください) 8. pyコードを作成して実行
GCPの設定関係(手順2〜5)
まずは、GCPでプロジェクトを作成して、Speech To Text APIを有効化して、APIを実行するための認証情報を作成していきます。
GCPプロジェクトの作成
まずは、以下のURLに飛んでいただき、GCPのコンソールへ移動します。
Step1:上記リンクをクリックすると以下のような画面が出てくるので、右上のconsoleをクリック

2. GCPで新規プロジェクトを作成する
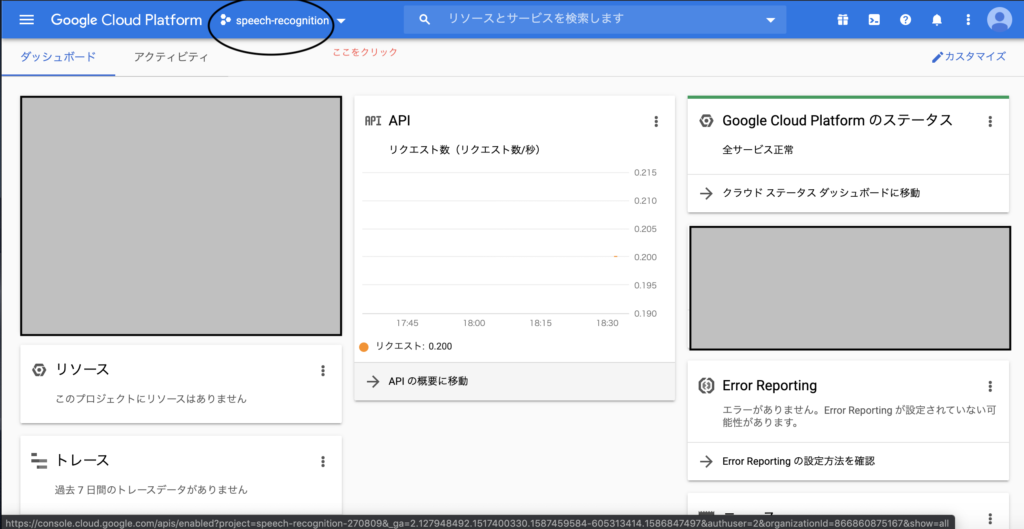
コンソールにログインすると以下のような画面が表示されますので、プロジェクトを新規作成するための、丸で囲われた部分をクリックしてください。
注:私のコンソールではすでに複数pjが立ち上がっているので、以下のような画面になっています。何もない場合は、空っぽなはずです。
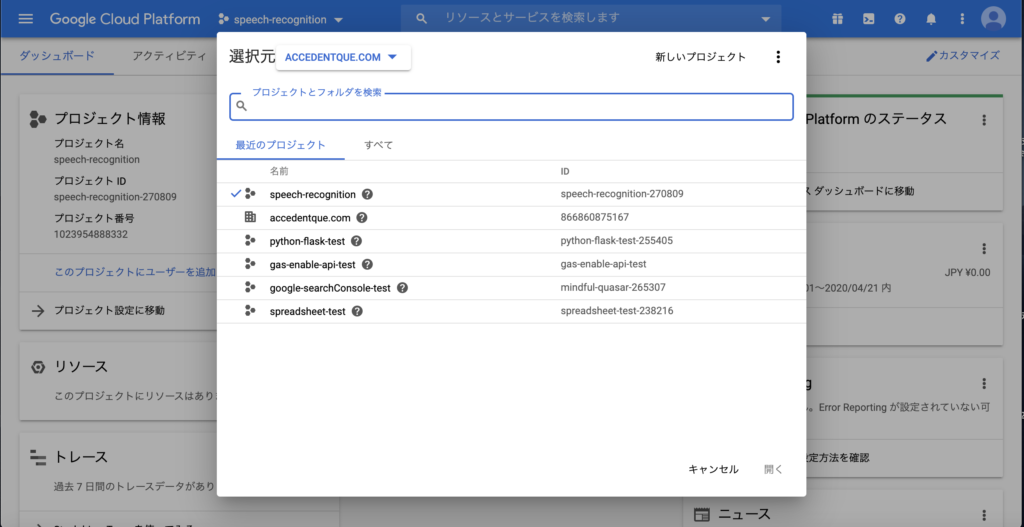
クリックすると以下のようなプロジェクト一覧画面が立ち上がります。新しいプロジェクトを選択してください。
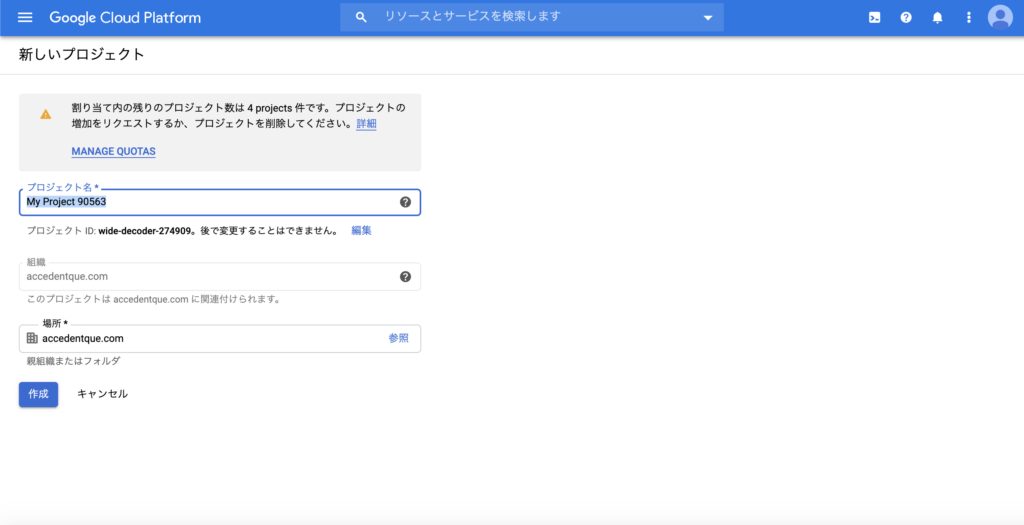
そうすると、プロジェクト新規作成画面が表示されますので、プロジェクト名等を入力して作成ボタンをクリックします。
新規でプロジェクトができるまで1〜2分くらいかかりますが、これでプロジェクト作成が完了です。
step3: プロジェクトでSpeech To Text APIを有効にする
作成したプロジェクトのダッシュボード画面左上にある、収納Windowを展開して、APIとサービス>ライブラリに移動します。
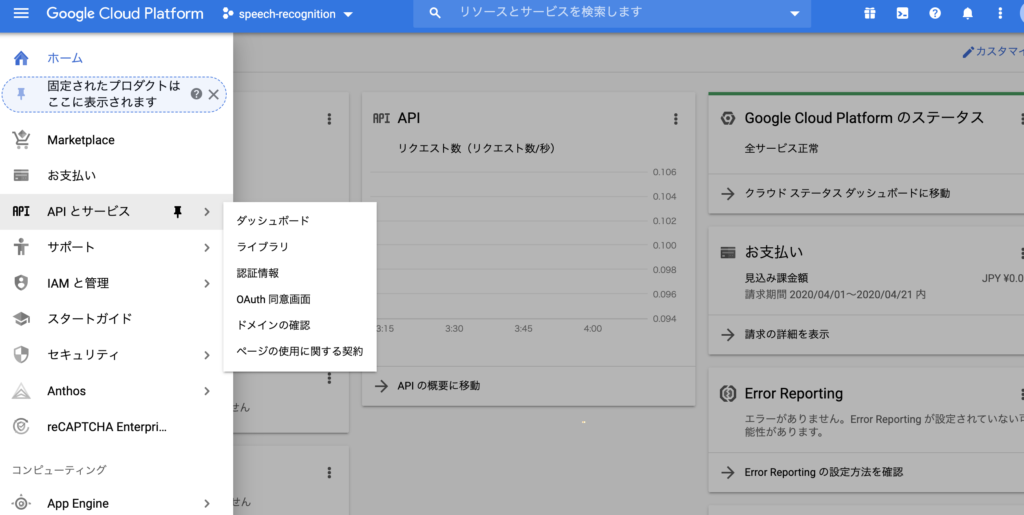
ライブラリでは、speechと検索画面に入力していただければ、Speech To Text APIが表示されます。なお、Text to Speech APIも表示されますので、間違えないように。
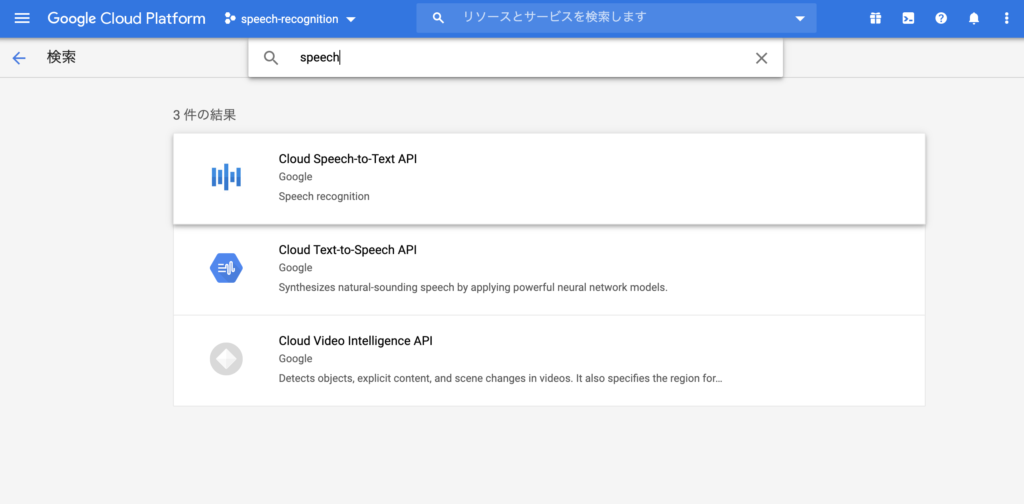
Step4: 認証情報を作成する
認証情報の作成方法は以下の記事で、sheet API利用した場合に作成した方法が紹介してありますので、基本処理方法は類似なので、ご確認ください。
Libraryのインポート関係(手順7)
いらないのも複数入っているのですが、気にならない方は、前回提示したライブラリ一式をrequirement.txtか何かに入れて、pipでインストールしておいてください。
appdirs==1.4.3 attrs==19.3.0 black==19.10b0 cachetools==4.0.0 certifi==2019.11.28 chardet==3.0.4 click==7.1.1 entrypoints==0.3 flake8==3.7.9 google-api-core==1.16.0 google-auth==1.11.2 google-cloud-speech==1.3.2 googleapis-common-protos==1.51.0 grpcio==1.27.2 idna==2.9 mccabe==0.6.1 pathspec==0.7.0 protobuf==3.11.3 pyasn1==0.4.8 pyasn1-modules==0.2.8 PyAudio==0.2.11 pycodestyle==2.5.0 pyflakes==2.1.1 PySimpleGUI==4.16.0 pytz==2019.3 regex==2020.2.20 requests==2.23.0 rsa==4.0 six==1.14.0 SpeechRecognition==3.8.1 toml==0.10.0 typed-ast==1.4.1 urllib3==1.25.8
なお、一点依存関係の問題でpyaudiを利用する場合は、brewにportaudioを入れるが必要あります。pyaudioをpipにインストールする前に、homebrew側でインストールを完了させておいてください。
まとめ
さて、事前準備が完了しました。
次回からはついに実際のスクリプトを見ていきたいと思います。全体像を最初に示しつつ、また部分部分を解説していければと思いますので、何回かに分かれる可能性がありますことをご容赦ください。
コロナで大変な時期ですが、こんな時期だからこそ自己学習や今まで作れなかったものに取り掛かる時間ができているかもしれません。after コロナという言葉は個人的にはまだまだ早いと思っているので、with コロナでやれることをやって、afterコロナ/ withコロナどちらでも自分の能力をpolishしていきたいものですね。
それでは。
関連記事: python speech to text APIを利用して音声認識ファイルを文字起こししてみよう
pythonでGoogleが提供するspeech to text APIを利用して音声認識ファイルを文字起こししてみます。speech to text APIの基本的な使い方、Macでのマイクを利用したwavファイルの作成方法、pythonでのメジャーGUIツールを利用した感想などを紹介していきます。
- python: speech to text APIを利用して音声認識ファイルを文字起こししてみよう
- python: speech to text APIを利用して音声認識ファイルを文字起こし〜シリーズ2 手順説明〜
- python: speech to text APIを利用して音声認識ファイルを文字起こし〜シリーズ3 スクリプト説明(1)〜
- python: speech to text APIを利用して音声認識ファイルを文字起こし〜シリーズ4 スクリプト説明(2)〜
- python: speech to text APIを利用して音声認識ファイルを文字起こし〜シリーズ5 スクリプト説明(3)〜