さて、先月ノンプロ研メンバーで盛り上がったpythonでspeech-to-text apiを利用してtranscript(文字起こし)を行う管理ツールの作成シリーズを初めていきたいかなと思います。
ことの発端は以下のようなslack投稿からでした。

あぁこういうのきたら盛り上がっちゃうよね、という部類に属する私はすぐさま飛びついて作成を開始しましたw
ネタだししていただいた方からのblog化OKもらったので、ゆっくりではありますが、少しずつ記事化していきたいと思います。
成果物イメージ
なにはともあれ、まずは成果物のイメージを共有させていただきます。
ざっと10秒くらいの音声入力をGUI経由で実施して、それをGUI上で文字起こししています。
設計イメージ
ざっくりとした概要は以下のようなイメージになります。
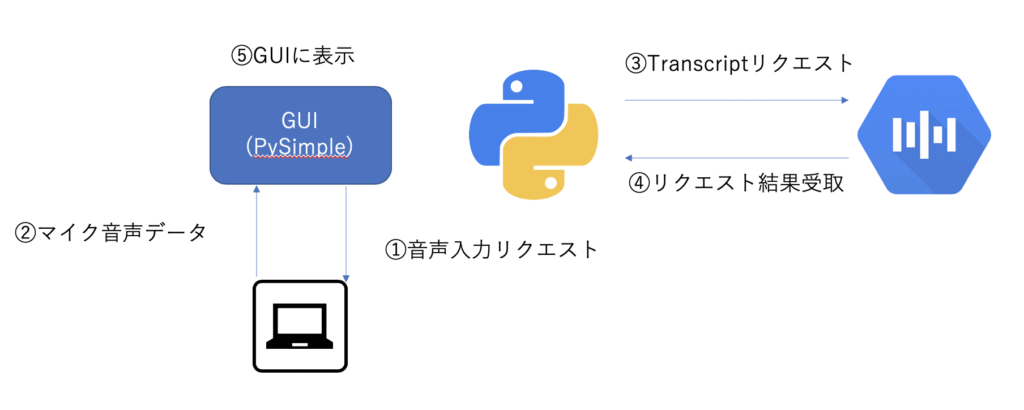
GUIから、マイク音声データを作成(音声認識)して、googleのspeech to text APIを利用して文字起こしをしていきます。
なお、speech to text APIは1分未満のファイルであれば、同期で文字起こし結果を返します。他方、1分以上のデータの場合は、非同期になりますので、文字起こし結果をすぐには表示できませんので、ご留意ください。
注)googleのspeech-to-text apiで1分指定されているapi endopointに1分以上のデータを投げ入れると、上限byte数が取れます(Request payload size exceeds the limit: 10485760 bytes.)。1分=10485760bytesの想定のようです。
実行環境
以下の環境で実行していきます。
#pycharm環境 python 3.7
説明していく音声認識+文字起こしの環境導入ライブラリは以下です。
appdirs==1.4.3 attrs==19.3.0 black==19.10b0 cachetools==4.0.0 certifi==2019.11.28 chardet==3.0.4 click==7.1.1 entrypoints==0.3 flake8==3.7.9 google-api-core==1.16.0 google-auth==1.11.2 google-cloud-speech==1.3.2 googleapis-common-protos==1.51.0 grpcio==1.27.2 idna==2.9 mccabe==0.6.1 pathspec==0.7.0 protobuf==3.11.3 pyasn1==0.4.8 pyasn1-modules==0.2.8 PyAudio==0.2.11 pycodestyle==2.5.0 pyflakes==2.1.1 PySimpleGUI==4.16.0 pytz==2019.3 regex==2020.2.20 requests==2.23.0 rsa==4.0 six==1.14.0 SpeechRecognition==3.8.1 toml==0.10.0 typed-ast==1.4.1 urllib3==1.25.8
今後説明する流れ
何回の記事に分けるかはよく考えていないのですが、ざっと以下のような流れで説明していきたいと思います。
- 手順説明(ローカル環境の設定や、GCP関係の設定など)
- 利用するコードの説明
- pythonのGUI関係の説明(補足)
まとめ
記事化しようかなぁと思ってから、1ヶ月以上放置していた案件ですがついに重い腰をあげようかなと思います。
何回かに別れる長いシリーズ記事になるかもですが、実際に誰でも音声認識や文字起こしはAPIを利用すればできる時代になっているという感覚をもってもらえればいいかなと思っています。
ノンプロが機械学習や深層学習を深く利用する機会は少ないかと思いますが、ちょっとしたことを自動化する際に、音声認識や画像認識などはどうしてもリアルデータからデジタルデータへの置き換えで必要になるプロセスです。
学習モデルを勉強する必要は少ないかもしれませんが、実際に使えるように公開されているものを利用できるようにはなっていきたいですね。
関連記事: python speech to text APIを利用して音声認識ファイルを文字起こししてみよう
pythonでGoogleが提供するspeech to text APIを利用して音声認識ファイルを文字起こししてみます。speech to text APIの基本的な使い方、Macでのマイクを利用したwavファイルの作成方法、pythonでのメジャーGUIツールを利用した感想などを紹介していきます。
- python: speech to text APIを利用して音声認識ファイルを文字起こししてみよう
- python: speech to text APIを利用して音声認識ファイルを文字起こし〜シリーズ2 手順説明〜
- python: speech to text APIを利用して音声認識ファイルを文字起こし〜シリーズ3 スクリプト説明(1)〜
- python: speech to text APIを利用して音声認識ファイルを文字起こし〜シリーズ4 スクリプト説明(2)〜
- python: speech to text APIを利用して音声認識ファイルを文字起こし〜シリーズ5 スクリプト説明(3)〜
