
さて、以前pythonで文字起こしをするツールを使って遊んでみました。GUIの勉強やgoogleのspeech to text APIの使い方などが学べました。
ただ、実際は自分で作ったより、大手のツールを使った方が楽にできるだろうということで、今回は2019年秋ごろに東京リージョンでも対応できるようになった、Amazon Transcribeを使って文字起こしをしてみたいと思います。
読んで欲しい人
- Amazon Transcribeに興味がある
- 文字起こし機能を自分で実装するほどではないけど、使ってみたい
- 議事録作成、インタビューの文字起こしに疲れている人
- mp3/mp4/wav/flacファイルの文字起こしをしたい人
- S3に音声データを保管している人
Amazon Transcribeとは?
Amazon Transcribeとは、AWS(Amazon Web Service)で提供されるサービスの1つで、自動で文字起こしをしてくれるサービスです。
2019年11月頃に日本語対応して話題になりました。自動音声認識で、音声ファイルや動画ファイルの文字起こしをしてくれます。
GCP speech to text APIとの違いは?
認識精度の違いはあるにせよ、両方とも音声ファイルなどを文字起こししてくれるという意味では同じです。
違いとしてあるとすれば、Amazon TranscribeはGCP speech to text APIと違いGUI(画面で操作すること、 graphical user interfaceの略)を提供しており、スクリプトを書かない人でも利用が容易です。
まぁAPIじゃなくてGUIを用意してるあたりがAWSっぽいといえば、っぽいですね。
Amazon Transcribeの使い方
使い方は至ってシンプルです。以下のステップで実行可能です(AWSに慣れていない人はわかりにくいかもしれませんが、ご容赦ください)
- AWSにログイン(rootでもIAMユーザでも権限があればどちらでもOK)
- S3にバケットを作る
- S3のバケットにファイルをアップロードする
- Amazon Transcribeでjobを作成する
- 文字起こしが完了するのを待つ
さて、1つずつざっとみていきましょう。
step1: AWSにログイン(rootでもIAMユーザでも権限があればどちらでもOK)
普通にAWSのログイン画面です。私はIAMユーザでログインするので、IAM用の画面になっています。
IAMユーザとかrootユーザの概念がわからない場合、また、AWSにアカウントを持っていない場合は、少しググってアカウント作成やIAMユーザの作成をしてみましょう。特段難しいことはありません。
step2: S3にバケットを作る
AWSのマネジメントコンソールから、サービス検索でS3を探してもいいですし、全てのサービスから見つけ出してもいいです。
S3に遷移すると以下のような画面が出てくるので、バケットを作成してください。リージョンはアジアパシフィック(東京)で大丈夫です。
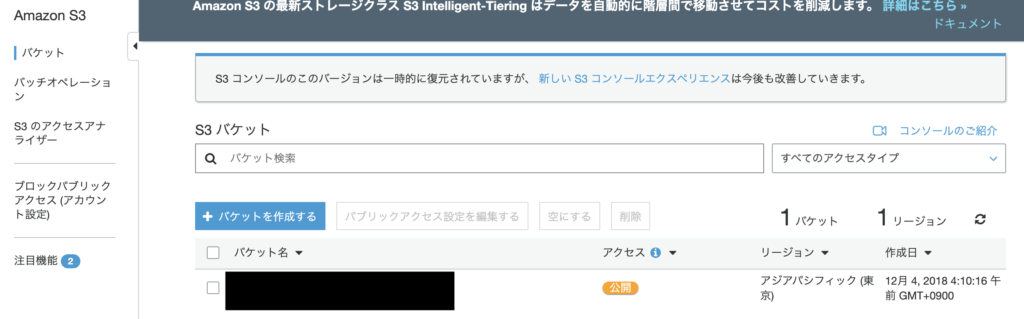
自分はすでにバケットが作ってあるので、既存の公開バケットを利用します。
step3: S3のバケットにファイルをアップロードする
まぁまんまですね。文字起こしをしたいファイルをS3にアップロードしてください。

step4: Amazon Transcribeでjobを作成する
さて、ついに本題のTranscribeを使っていきます。マネジメントコンソールからTranscribeを検索します。
Amazon Transcribeを指定して、Transcribeのサービスページに移動します。以下のような画面が出てきます。
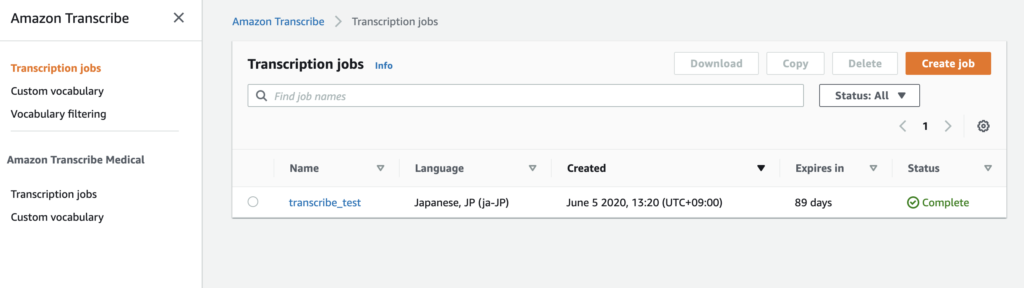
【create job】をクリックします。以下のようなジョブセッティングの画面が出てきます。

設定内容は以下です。
Name: ジョブの名前(後から何を文字起こししたのかわかるようになってればなんでもOKです)
Language: Japanese, JP(ja-JP)を選択
input data: 先ほどデータをアップロードしたバケットを入力。Browse S3ボタンをクリックするとバケットの詳細が表示されるので、対象の音声ファイルを選択します。
注:input dataを選択する際に、TranscribeのリージョンがS3バケットのリージョンと相違していると、バケットが表示されないので合わせてください。
あとは、細かい設定が続きますが、デファクトのまんまでも大丈夫です。
step5: 文字起こしが完了するのを待つ
あとは、ボーッと待つだけです。短いものなら1分ぐらいで、長いファイルでも30分ぐらいで文字起こししてくれます。
完了すると以下のような結果画面が表示されます。文字起こしされた内容も表示されます。画面切れちゃっていますが、この下の方に文字起こしテキストが出てきます。
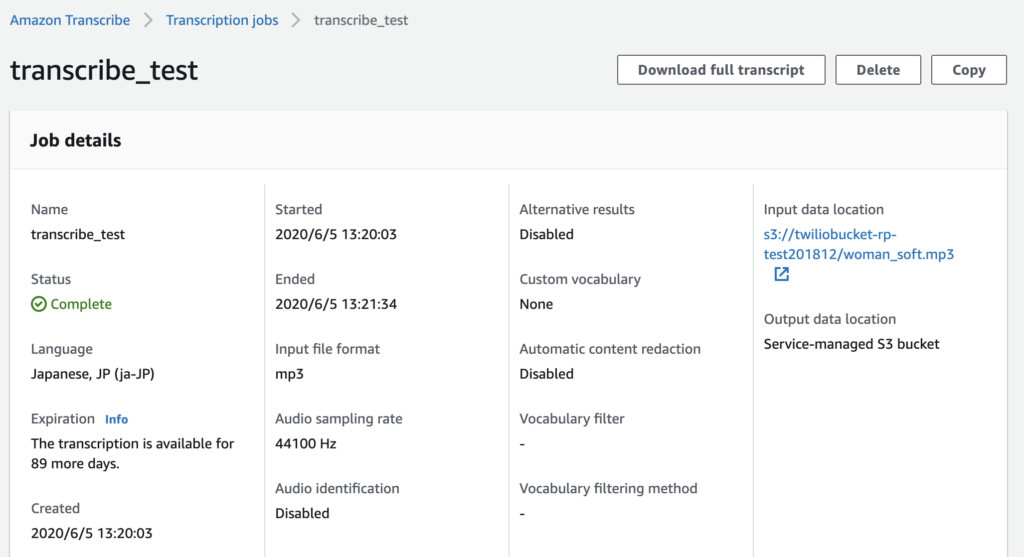
文字起こし結果をダウンロードする:DLファイルはJSONです
さて、文字起こしが完了して【Download full transcript】からデータをDLすると、なんとデータ形式はJSONでしたw
あっテキストじゃないのねw 個人的にはありがたいけど、ここだけは全くプログラミングわからない人向けではないかもですね汗
ということで、いつも通りpythonでざっと中身をみてみましょう。
import pprint
with open("/Users/sugimurakazuya/Downloads/asrOutput.json", "r") as f:
data = f.read()
pprint.pprint(data)
ジョブのリザルトや各チャンクごとのスタート・エンド時間やconfidenceなども返ってきています。結構親切なjsonだと思います。
文字起こし精度・コスト
気になる文字起こしの精度ですが、30秒ほどのファイルでしか試していないので、あくまで感覚ですが、まぁまぁいい感じ。もちろん音声ファイルのレベル(ノイズ削除してるかどうか、専門用語が少ないかどうかなど)に寄って、大きく左右される感じではありますが、ざっと文字起こしには十分なレベルかと思います。
コストは、大体1時間150円くらいでしょうか。詳細は以下のリンクをご確認ください。
まとめ
今回は自分でスクリプトを書かない文字起こしを紹介しました。
Amazon Transcribeを使えばノンプログラマーがローコストで簡易な文字起こしができると思います。GUIで全て対応できるので、スクリプトを書くのが億劫な人向けですね。